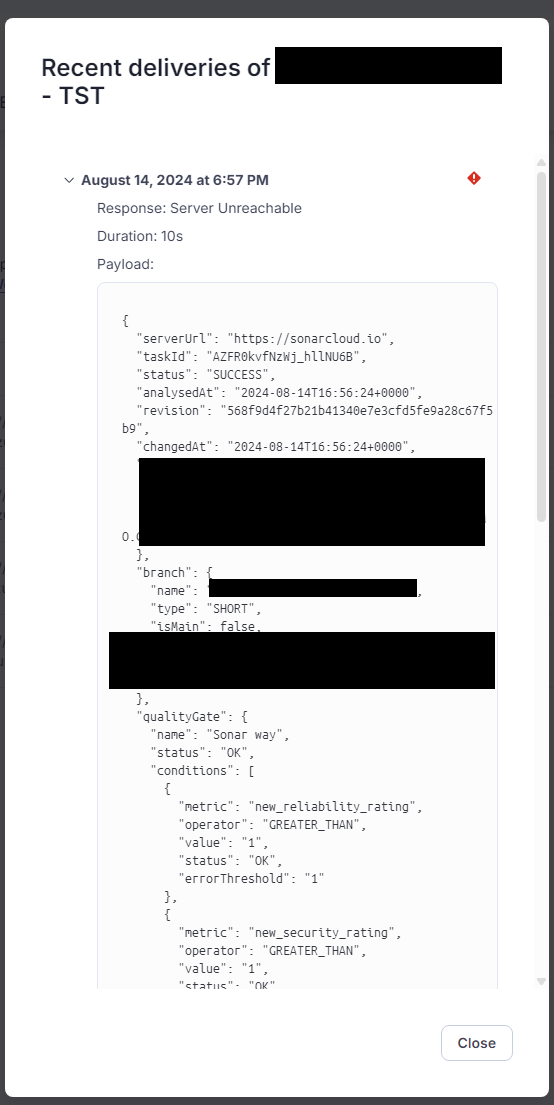
I am currently facing issues with webhooks in my organization. It seems that not all events are being delivered due to “Response: Server Unreachable”.
Response: Server Unreachable
Duration: 10s
This behaviour seems erratic and unexplainable considering the services that host the endpoints are all reachable by other requests in the same time period.
This issue is the same across all our webhooks in the organization to different environments of the same service but the periods in which events cannot be delivered do not seem to match up.
Is there someone that might help me in getting the root cause of this clear?
That’s really curious because the logs show that a 200 was returned on at least these two tasks
AZFLJD47Gn4pEHFLSLhS
AZFLX3KBF1KYu4EHFDym
In the past 4 weeks, the Webhook URL in these two task IDs (ending with SonarcloudWebhooks/ProjectAnalysisIsComplete) received 3,100 successful POST requests (status code 200), while only encountering a single non-200 status code (a 503 error).
Regardless of what SonarCloud is saying, can you confirm whether or not the webhooks are being delivered via some logging on the receiving end?
This I managed to correlate to a request internally that on 1 of the environments was causing the processing time to exceed 10 seconds. After breaching this the Client (Sonarcloud) seems to terminate the connection (HTTP 499).
Our processing time should never be this long and I have created a bug on our board to look into this. Could this be the reason these entries show up as red / failed in the UI?
It’s very possible, however something is definitely weird if you’re seeing an error in the UI but we aren’t logging any error in our internal logs. Our developers are going to look into it.
In the meantime, can you confirm to me if there’s only 1 webhook configured for this project, or multiple?
We took a look internally at your issue. If this internal request you mentioned takes more than 10 seconds, the delivery will be marked as failed (you can see this mentioned in our documentation).
Having said that, we took action on our side to improve our internal logs to be able to identify these types of issues in a better way next time this situation happens.
If you have any other questions or extra information, just let me know.