I’ve experienced something similar when Sonar is not reachable for any reason
(possibly also when just restarted and working hard at reindex, but not sure about this)
I agree if Sonar is not reachable then it is a middleware/newtwork issue.
But I suspect that when jenkins is not able to get a valid response calling sonar api, this leaves jelly threads with locks on the jenkins jvm side, always tied to caffeine cache.
The side-effect on the UX is that some multibranch jobs become unreachable from jenkins UI.
Not sure if this would lead those thread hanging indefinitely on jenkins jvm, cause I had to restart the service in order to make it operational again.
HI Ann, we don’t have persistent logs collector on this system, so I’ve tried to reproduce it locally using a simple docker-compose: no success.
I’m going to try turning off sonarqube during night in production and get the relevant logs.
I was not able to reproduce the issue locally with a docker-compose config.
So I turned off the production instance of sonarqube and collected some logs, though it should be noted that this time I can’t see any effect on the jenkins thread dump, that is no threads remained indefinitely hanging.
jenkins connects to the proxied-dormant-domain I just shut down to trigger the issue, obtaining from the nginx proxy a 503 response with html
jenkins tries to connect to old-unreachable-domain1 and old-unreachable-domain2, both of which are not reachable, so the connetion is reset or have issues during SSL handshaking
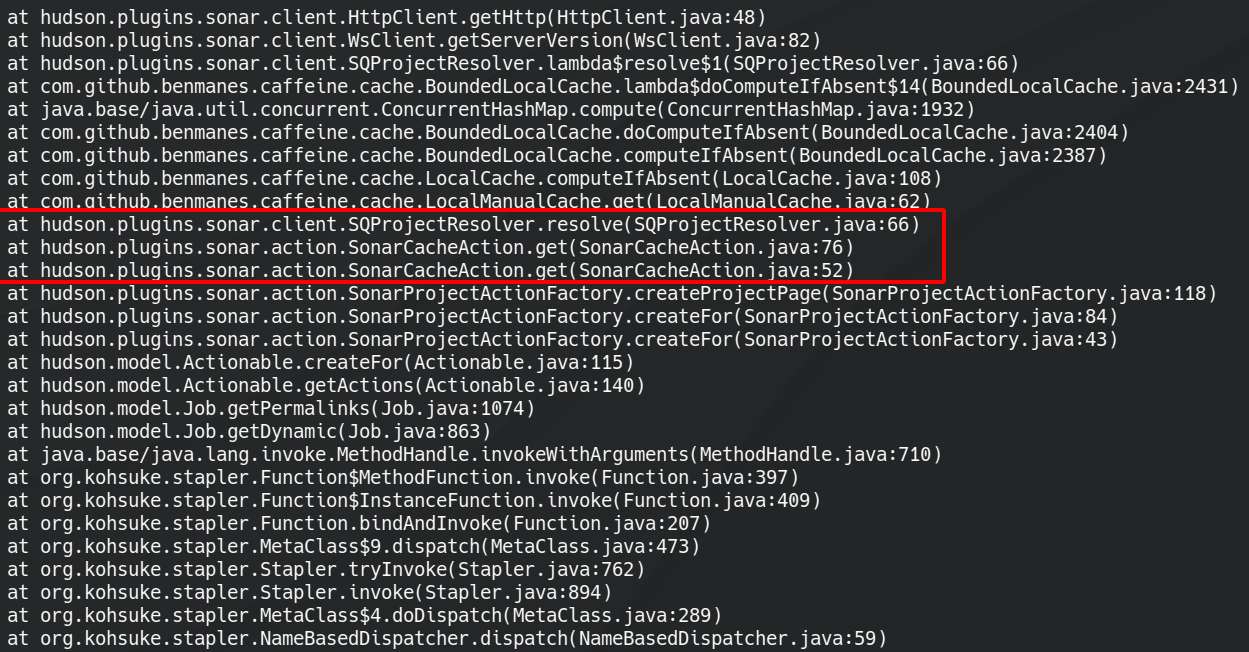
Monitoring the thread stack I can see that the http client connects (or tries) to sonarqube instances related to old job executions. Sometimes these are old domain names, moved to other domains in the meantime, so they are not reachable now (going to update DNS records in order to avoid this).
This doesn’t imply any deadlock or other issues though, as the client fails, logs the issue and then frees up the thread.
So there should be some other factor in place (unknown to me) to properly reproduce the issue. The day I restarted the pod where threads were hanging I lose related logs and had no way to reproduce it.
BTW since it happened at least two times so far, I suppose it could happen again, and in that case I’ll collect all related logs.
For sure the production instance is concurrently accessed by jenkins users both using Blue Ocean and classic UI.
So in the meantime we updated the DNS records, but the k8s ingress is not updated yet.
Any way we have again a bunch of threads waiting to acquire locks on BoundedLocalCache from caffeine.
I’ve collected some thread dump from jenkins every 15 minutes: stack.zip (138.1 KB)