We are using SonarQube Developer Edition 9.8 (build 63668)
It is deployed via Docker, hosted in Azure VM
We are trying enforce quality gate on “New Code” via the Sonar Way quality gate
We follow the git flow branching strategy, and have set up Jenkins pipeline jobs capable of building/scanning each branch
Scans are mandatory for master, hotfix, and developer branches, but optional for other branches
When scans are run, the pipeline always use the -Dsonar.branch.name option and specify the branch name
When scanning non-master branches, the pipeline uses -Dsonar.newCode.referenceBranch=master to reference the master branch
When scanning the master branch, the pipeline does not specify the reference branch; SonarQube is configured to the “Previous version” as the default detection algorithm
Most of the time, this setup works fine. But in a few cases, we have this odd behavior, which is not always reproducible:
On a non-master branch (e.g. release), developers ensure quality gate passes
The development team then merges to master by running git flow release finish, after which a build on master is kicked off
But the analysis on master branch shows results different results than the scan on the release branch
This difference can mean that the scan on the release branch passes quality gate, but the scan on master does not, which leads to developer complaint.
For some projects, it fails on code coverage, saying the code coverage % for new code on master branch is lower than 80%, when the code coverage on release is higher than 80%.
For others, it fails on other items in the quality gate. I just received a report today for a scan that is complaining about 11 code smells and 59 minutes of technical debt when the scan is run on master, whereas on the release branch it shows zero code smells and no technical debt on new code when compared to the master branch.
Is there a way for us to know the commit hashes used by a particular scan? I am guessing perhaps different commits are being used as the reference branch depending whether I run the scan on master vs release branches.
Ehm… If the question is which commit is being analyzed, then there are several parameters that could help. You may be able to look up the value of sonar.scm.revision, altho TBH I have no experience with that particular parameter. Another option is the roll-your-own parameter: sonar.analysis.[yourKey], e.g. sonar.analysis.commitHash. The third option is passing in sonar.buildString, which should let trace the analysis back to your CI data.
If you’re asking which commit hash is being used as the new code baseline… For branches where the baseline is internal to the branch (i.e. previous_version) you can see that in the UI:
I will take a look at other sonar options you’ve recommended and see if that will help us.
Today, when scanning non-master branches, our current pipeline always set the sonar.newCode.referenceBranch=master parameter. When scanning master branch itself, it does not specify this parameter at all.
So, if the master branch of a repository currently has a version of 1.2 as its latest commit, and I have an open release/1.3 branch, then I expect a scan on the release/1.3 branch use the commit with version 1.2 on master as reference for determining new code. And, after release/1.3 is merged to master, I expect a scan on the master branch will use version 1.2 of master as reference for determining new code. This means a scan on release/1.3 or the master branch both should reference the same commit of master with version 1.2 for new code detection.
No. That’s not how it works. By pointing to main, you aren’t setting your branch’s baseline to be the same as main’s. You’re setting it to the point in the branch history when it diverged from main.
BTW, what you could do instead here is via the UI set the project New Code value to your main branch - this would kick in automatically for all new branches with no need to use the parameter - and individually set the main branch like you have it now.
Set it at the project level and it will apply to all branches (other than main) where it hasn’t been overridden. You may need to configure main separately.
I can set it at a project level. But we have 100+ projects, and new ones are being created all the time. Ideally, I would like to set it at the global level, and do a bulk apply once to configure the existing ones, and have the same apply to new ones created in the future. Is there a way to do so?
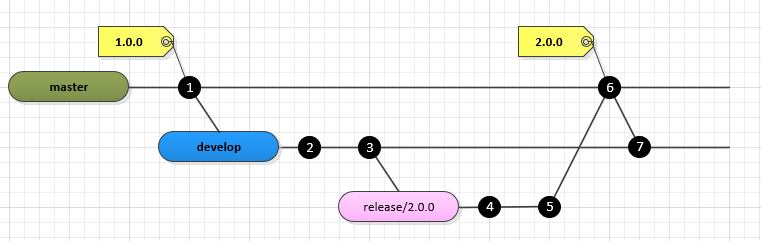
We are still struggling with this issue. Let me try to explain once more with the help of this diagram, which illustrates the git-flow process we are following.
Before release/2.0.0 branch is merged to master, whenever we run scans on the release/2.0.0 branch (commits #4 and #5), we specify -Dsonar.newCode.referenceBranch=master. In this case, I am expecting commit #1 of master to be used as reference for new code detection.
After the code has been merged to master (commit #6), when we run scans on the master branch, we do not specify any reference branch. Since the global setting for new code detection in our SonarQube is set to previous version, here I am also expecting commit #1 to be used as reference for new code detection.
This practice is enforced for all of our code repositories through the use of the git-flow plugin to git, and by our Jenkins pipelines.
However, we are not seeing this consistent behavior across all repositories. For some repositories, a scan of the release branch against master will produce one set of metrics, but a scan of master against the previous version of master will produce different metrics (code coverage, etc.).
To try and troubleshoot this annoying behavior, can you help me confirm whether my expectations as stated above are correct?
Also, is there a way for me to find out for any given scan, which commits are being used by SonarQube for new code detection?
In fact, this parameter only has an effect on the first analysis of a branch so it’s not doing anything on #5, and it’s only having an effect if #4 was the creation of the branch in SonarQube.
That aside, it’s honestly not clear to me how the intermediate develop branch affects these things.
A couple interesting excerpts from the docs:
(emphasis mine)
Choose a specific branch to define your new code. Any changes made between your branch and the reference branch are considered new code. When cloning a repository, we recommend that you clone all the branches to avoid reference errors.
Does this happen in your jobs?
When using any new code period type other than Reference Branch , we recommend completing your merges using the fast-forward option without a merge commit; examples include GitHub’s squash and merge or rebase and merge options. In this way, the blame for the merged commits will always have a more recent commit date.
I think this is going to apply when you merge release/2.0.0 back to master. What’s your merge strategy there?
I think it’s time to dig into what the exact differences are, and what the blame dates on the relevant lines are.
Hi, Ann. Thanks for continue to engage with me on this thread.
To clarify, when the release/2.0.0 branch is first created, there is no new commit recorded in Git, as it is identical to develop at its creation. The first change introduced to release/2.0.0 branch happens with commit #4. But, what you stated does not make sense to me. If the reference branch parameter only has effect on commit #4, what does SonarQube do for new code detection on commit #5?
We do clone all branches (and tags) in our pipelines. In fact, I introduced a recent change to force a clean clone by wiping out the working copy to ensure we have up-to-date code base for SonarQube scans across all branches.
We are using the gitflow-avh plugin to carry out our branch/merge strategy. I tried it on a test repo by running the "git flow release finish --showcommands" from the command-line, which carries out these commands, based on the output when I add the
git fetch -q origin release/2.0.0
git checkout master
git merge --no-ff release/2.0.0
git tag -a 2.0.0
git checkout develop
git merge --no-ff 2.0.0
git push origin :release/2.0.0 # deletes the release/2.0.0 branch
Then we push up all changes, including tags, up to the remote:
It uses the value you set in the analysis of commit 4. You only need to set this once per branch. It was just an FYI. It’s fine to leave it in your parameters. Just know that if you subsequently change the value for an established branch, it won’t have any effect.
Here is a fresh occurrence of this problem. Below is what the Git commit graph looks like. The black line represents the master branch, and the green line that merges into master and the 6.61.0.0 tag represents the release/6.61.0.0 branch.
The most recent scan of release/6.61.0.0 branch referencing master as new code passes quality gate, but after it is merged to master, a scan of master referencing the previous version tag of 6.60.0.2 does not. As you can see, there were no other commits to master between the two tags, so I’m at a loss as to why the two scans would show different results, as both should be referencing the same commit on master for new code detection.
While your observation is superficially correct, I don’t understand why SonarQube thinks there is a difference. Both scans are performed by referencing master branch from for new code detection. Between when the release/6.61.0.0 branch was created and when it was merged into master, there were no other changes made to master, as indicated by the branch graph I shared. So, based on my understanding, the two scans should produce the same results. I’d like to understand why SonarQube behaves this way, and if there is something we are not doing correctly that is causing this misbehavior.